Nesse artigo será mostrado com Java como extrair textos editáveis de imagens utilizando o OCR (Optical Character Recognition) Tesseract, com o auxílio do wrapper tess4j para o código. Não é necessário ter muita experiência em Java, mas é recomendado que tenha familiaridade com comandos básicos do Linux.
A imaginação é mais importante que o conhecimento.
– Albert Einstein
Uma breve história
![]()
Fonte: GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engine
O Tesseract foi originalmente desenvolvido na Hewlett-Packard Laboratories Bristol e na Hewlett-Packard Co, Greeley Colorado, entre os anos de 1985 a 1994, com mais algumas mudanças, foi portado para Windows em 1996, além de alguns aprimoramentos em 1998. Em 2005 foi liberado a comunidade pela HP e desde 2006 é desenvolvido pela Google. Mais informações sobre Tesseract podem ser encontrada em https://github.com/tesseract-ocr/tesseract.
Optical Character Recognition
Segundo a Wikipédia:
OCR é um acrônimo para o inglês Optical Character Recognition, é uma tecnologia para reconhecer caracteres a partir de um arquivo de imagem ou mapa de bits sejam eles escaneados, escritos a mão, datilografados ou impressos. Dessa forma, através do OCR é possível obter um arquivo de texto editável por um computador.
O Tesseract é uma implementação de OCR de código aberto capaz de reconhecer mais de 100 línguas (configuráveis) com caracteres Unicode. Também é possível ensinar a reconhecer novas linguagens e padrões através do suporte a técnicas de machine learning disponível na biblioteca.
Basicamente o Tesseract funciona como uma aplicação de terminal, cuja API (libtesseract) é construída em C/C++. Para utilizar com Java é necessário utilizar chamada nativa (JNI/JNA) ou recorrer para umwrapper chamadoTess4j.
O Tess4j
De forma simples o Tess4J é um wrapper (um invólucro) que utiliza Java Native Access (JNA) para abstrair a integração nativa (C/C++) e expor a API do Tesseract através de classes e métodos Java.
O projeto foi criado pelo usuário Quan Nguyen em 2012, e vem tendo contribuições pela comunidade através do Github. O projeto está crescendo em popularidade, mas possui pouca documentação e exemplos, o que pode dificultar um primeiro contato de iniciantes. Apesar dos obstáculos o projeto está bem ativo e tem um fórum de discussão em Tess4J / Discussion / Help no SourceForge, que é uma fonte rica para quem tem familiaridade com o inglês. O suporte a problemas é realizado através do projeto no Github em Issues · nguyenq/tess4j · GitHub e continua bem ativo.
Configuração
Para utilizar a biblioteca do Tess4j é necessário apenas baixar a lib nas releases no GiitHub ou utilizar um gerenciador de dependência configurado com o repositório do Tess4j. Como o Tess4J é uma camada acima do Tesseract é necessário ter o mesmo configurado no sistema operacional, em Windows é necessário apenas instalar o Visual C++ 2015-2019 Redistributable, pois as libs são carregadas dinamicamente do próprio jar da lib.
No Linux também é simples, basta instalar pelo gerenciador de pacotes da distribuição utilizada conforme a documentação, caso tenha uma distribuição baseada em Ubuntu pode seguir esses comandos:
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-por
Os comandos instalam o Tesseract com suporte a língua portuguesa.
Codificando
Na internet realizei uma pesquisa sobre modelos de ofícios judiciais e logo encontrei a seguinte imagem:

A imagem possui uma boa qualidade e atende bem os requisitos do Tesseract. O projeto de exemplo foi criado para ser construído em Maven, logo é necessário configurar a dependência:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.2</version>
</dependency>
No projeto a imagem foi colocada em src/main/resources como teste.png, sendo criada a classe LerImagem.java com o seguinte código:
package com.ivanqueiroz.tess4tj.app;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
import java.io.IOException;
public class LerImagem {
public static void main(String[] args) throws IOException {
File imageFile = new File("./src/main/resources/teste.png");
Tesseract tess4j = new Tesseract();
tess4j.setDatapath("/usr/share/tesseract-ocr/4.00/tessdata");
tess4j.setLanguage("por");
try {
String result = tess4j.doOCR(imageFile);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
No Linux é necessário configurar o Datapath do Tesseract além da linguagem do texto (no caso português). Após passar a imagem para o método doOcr o retorno é a String resultante do reconhecimento, que ao ser impressa, traz o seguinte resultado:
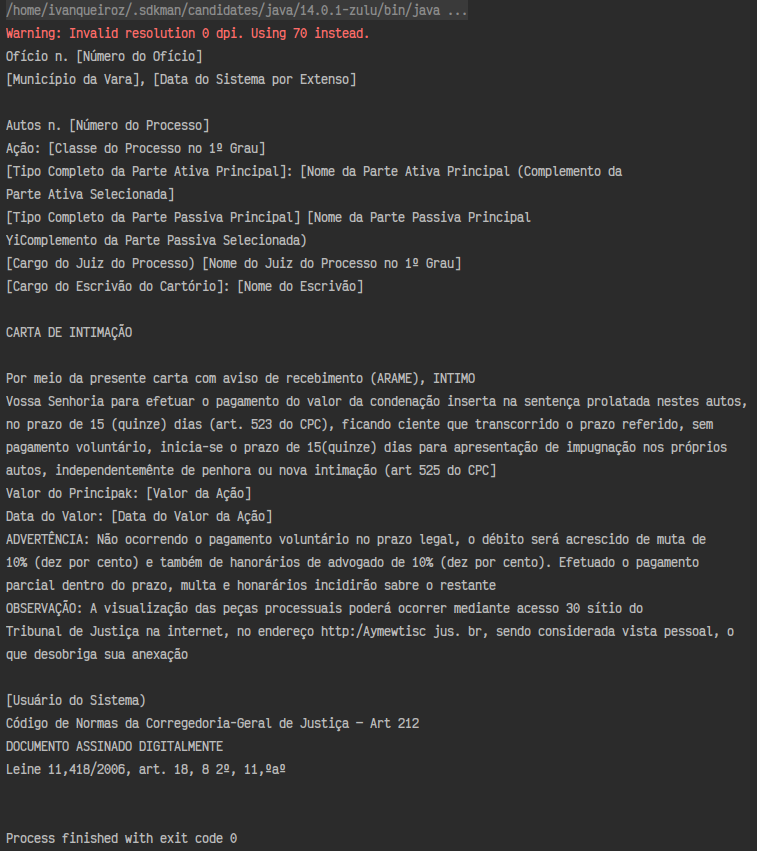
A taxa de assertividade foi bem alta, e poderia ser contornada com algum processo de correção de texto posterior.
Observações
O programa de exemplo é bem simples, nele o Tess4J recebe uma imagem e retorna uma string. Para o sucesso do OCR a qualidade da imagem utilizada influencia diretamente no grau de sucesso do reconhecimento, na documentação do Tesseract é recomendado que para um melhor desempenho a imagem possua:
dois canais de cores somente (preto e branco);
mínimo de 300dpi de resolução;
possuir o texto em um único idioma;
sem bordas excessivas no texto;
texto alinhado e sem ruídos;
altura do espaço superior ocupado pelo texto de no mínimo 10px.
O Tesseract já realiza um processo interno que segue esses passos, mas algumas vezes não é o suficiente.
Finalizando
Pretendo abordar em um futuro artigo, como melhorar as imagens adquiridas utilizando uma biblioteca que manipule a imagem buscando torná-la mais fácil de ser reconhecida para o Tesseract.
Disponibilizei o código em GitHub - ivanqueiroz/tess4tj: Exemplo de utilização do Tess4J para quem se interessar como base de estudo.
Espero trazer nova versão desse pequeno programa em um futuro artigo. Até a próxima!
Fontes
https://tesseract-ocr.github.io
GitHub - nguyenq/tess4j: Java JNA wrapper for Tesseract OCR API